[Applied Predictive Modeling 4] Special Classification Problem
타겟 분포 불균형 문제 해결해보자.
- target balancing methods
- class weight, undersampling, oversampling 기법
- train데이터에만 under, oversampling 적용해야함
- 프로젝트에 사용할 데이터의 불균형 문제를 진단하고, 균형을 맞춰주는 기법 적용
- 지금까지 배운 선형 모델, 트리 기반 모델로 다중 클래스 분류 문제를 해결하기 위한 모델링 수행 가능
- 앙상블 기법을 활용해 불균형 분류 문제 해결
🌀 Scaling
(복습)
각 feature은 각자 다른 단위를 가지고 있다. 이러한 단위 차이는 몇몇 회귀 모형이나, 머신러닝 기법에서 문제를 일으킬 수 있다.
또한, 거리 기반의 모델링 시, 상대적으로 범위가 넓은 변수는 거리 계산에 더 많은 기여를 하게 되어, 더 중요한 변수 영향력이 높은 변수로 인식될 수 있다.
이러한 문제를 방지하기 위해 하나의 범위로 재정의하여, 모델에 동일한 기여를 할 수 있도록 일반적으로 수행해준다.
가장 잘 알고 있는 기법으로는, z-score(standardization) mean=0,std=1 / MinMaxScaling(normalization) 0~1
scaling 꼭 필요로 하는 것
- PCA (주성분 분석)
- 높은 분산/넓은 범위를 가지는 변수 : 낮은 분산을 가지는 변수보다 주성분에서 큰 회귀계수를 가진다. → 중요하지 않은 변수도 범위가 넓으면 주성분에서 중요한 변수로 간주되어 치명적이다.
- Clustering
- 거리-기반 알고리즘으로 거리 측도를 이용하여 관측값 사이에서 유사성을 찾아 군집을 형성한다. 따라서, 넓은 범위를 가지는 변수는 군집에서 더 큰 영향력을 가지게 된다.
- KNN
- 거리-기반 알고리즘으로 새로운 관측값의 주변에 있는 k개의 이웃을 이용하여 유사성 측도에 기반해 관측값 분류한다. → 유사성 측도에 모든 변수가 동일하게 기여할 수 있도록 해야한다.
- SVM
- 서포트벡터머신은 서포트벡터와 분류기 사이 거리인 margin을 최대로 만들어주는 분류기를 찾는 알고리즘이다.
- 큰 값을 가지는 변수가 거리 계산을 할 때 영향력을 많이 미치게 된다.
- Regression
- 예측을 위한 회귀 모델링이 목적이라면 스케일링을 꼭 해줄 필요는 없다.
- 하지만, 변수의 중요도나 다른 회귀계수들과 비교를 하는 것이 목적이라면 스케일링해줘야함.
- Ridge, Lasso
- 규제기법으로서, 회귀계수에 alpha값을 주면서 다중공산성, overfitting을 해결하기 위해 사용된다.
- 회귀계수의 크기를 페널티값으로 사용하기 때문에, 상대적으로 큰 분산을 가지는 변수가 회귀계수가 클 것이며, 그 회귀계수를 페널티값으로 사용하게 되면 작은 분산을 가지는 변수들보다 회귀계수를 더 축소시켜 최종적인 회귀계수는 더 작아지게 될 것이다.
- 회귀계수가 단위에 영향을 미치기 때문에 표준화를 꼭 수행해주어야한다.
scaling이 필요하지 않은 경우
- Logistic Regression
- Tree Based Model - Decision Tree, Randomforest, Gradient Boosting : 변수의 크기에 민감하지 않으므로 표준화 수행해줄 필요가 없다.
🌀 Class Imbalance 문제
현업에서 매우 불균형한 타겟 분포를 갖는 분류 문제를 많이 마주하게 된다.
model fit시, 전체 오차가 가장 적은 모델을 만들려고함.
클래스 불균형 문제의 경우 보통 알고리즘이 다수 클래스를 더 많이 예측하는 쪽으로 모델이 편향되는 경향이 있다.

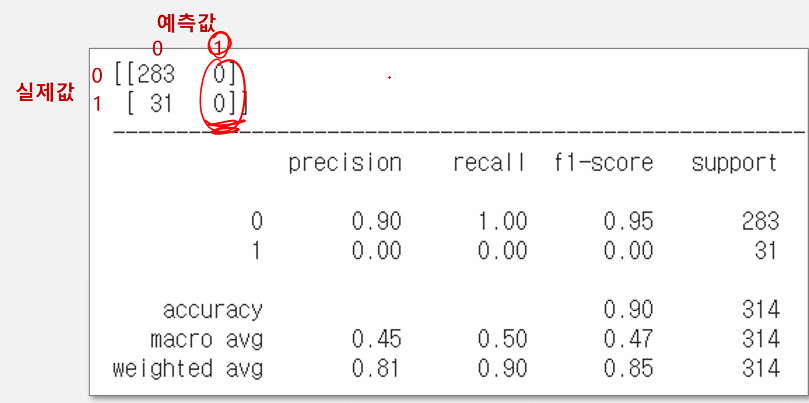
타겟 불균형 시, accuracy나 auc만 볼 것이 아니라,
classification_report를 보며 전체적으로 봐줘야함. (precision, recall)
해결 방법
- resampling : 물리적으로 1대1 비율 맞추기 (훈련 데이터셋에서만 resampling해줘야함.)
- class weight 조정 : 오차에 가중치 부여
두 가지 방법은 전반적인 성능을 높이기 위한 작업이 아니라, 소수 class의 성능을 높이기 위한 작업이다!!
class_weight은 gridcv를 돌리며, 가장 좋은 가중치 비율을 찾아내는 것이 가장 좋을 것으로 보임!
두 가지 해결방법에 대해 알아보자~
Resampling
불균형 문제 해결책1 : 물리적으로 균형 맞추기
- downsampling : 다수 class의 데이터를 소수class수만큼 random sampling (비복원추출)
- upsampling : 소수 class의 데이터를 다수 class수만큼 random sampling (복원추출)
- smote : 소수 class데이터를 보간법으로 새로운 데이터를 만들어냄.

사실 resampling 하는 세 가지 방법 모두 비슷한 성능의 결과를 낸다.
class_weight 조절
불균형 문제 해결책2 : 오차 가중치 부여

class_weight=’balanced’: y_train의 class비율을 역으로 적용
class_weight={0:0.2, 1:0.8} : 비율 지정 or gridsearch cv (이것이 가장 좋은 성능을 찾아줄 것으로 보임)
cf) xgboost - scale_pos_weight
GridSearchCV로 가중치 비율 조정해보자!!!!
from sklearn.model_selection import GridSearchCV
wt0 = np.linspace(0.01, 0.99, 99) # 0.01~0.99까지 99개의 균일한 분포
params = {'class weight':[{0:x, 1:1.0-x} for x in wt0]}
model = GridSearchCV(SVC(kernel='linear'),
params,
cv=5,
scoring='f1')
model.fit(x,y)
model.best_params_
>> {'class weight':{0:0.22, 1:0.78}}앙상블 기법 적용
(unsampling + bagging) : BalanceBaggingClassifier
- unsampling : 다수 데이터의 큰 손실 발생
- 여러 번의 unsampling하여 각 분류기를 만든 후, 분류기들의 결과를 평균낸다면 다수 데이터에서의 정보 손실을 줄일 수 있을 것이다.
from imblearn.ensemble import BalanceBaggingClassifier
model = BalanceBaggingClassifier(SVC(kernel='linear'),
n_estimators=50,
random_state=42)
model.fit(x,y)
pred = model.predict(x)
print(confusion_matrix(y, pred))
print(classification_report(y,pred))
>>
[[889 79]
[ 2 30]]
============================================================
precision recall f1-score support
0 1.00 0.92 0.96 968
1 0.28 0.94 0.43 32
accuracy 0.92 1000
macro avg 0.64 0.93 0.69 1000
weighted avg 0.97 0.92 0.94 1000
기본적으로 불균형 타겟 분류 문제는 좋은 성능을 내기 어렵다.
class_weight, undersampling, oversampling같은 기법을 사용하되, 성능을 고도화하기 위해 추가로 앙상블, gridsearch cv등을 사용할 수 있다.
불균형 타겟 분류 문제의 성능 확인을 위해, accuracy, auc 등을 단순히 사용하면 안되며,
confusion_matrix를 함께 확인해 어느정도의 성능이 나오는지 확인해야한다.
More Study
앞서 수동으로 class weight를 조절해보았다.
class weight 조절하는 방법 중 하나로, log loss를 사용하는 방법도 있다.

log loss : 이진 분류 문제에서 예측된 확률값과 실제 레이블을 비교하여 오차를 계산하는 방법이다.
이렇게 가중치를 반영한 log loss를 최소화하는 방향으로 모델을 학습할 수 있다.
이를 위해서는 log loss를 최소화하는 optimizer를 선택해야한다. (일반적으로, 로지스틱 회귀에서는 SGD, Adam optimizer를 사용한다.)

인공지능 모델의 결과를 어떻게 비지니스 성과로 연결하나?
모델을 f1, recall, pre등으로 평가했다면,
모델을 돈으로 평가해보자.
- 모델의 성적표 계산
1인당 기대수익액을 계산할 것이므로, confusion matrix를 비율로 변환.
- 비지니스 가치 matrix (중요!!!!)
우리가 예측한 모델로 고객은 어떤 액션을 취하는지 정해야한다.
- 액션
- 신용도가 낮게 예측된 고객 → 신용대출신청 반려
- 신용도가 높게 예측된 고객 → 신용대출신청 승인
- 이런 액션으로 어떤 일이 벌어질까?
- 신용대출신청 반려 → 신용도가 낮은 고객 맞았을 때(아무일도 안일어남) 혹은 틀렸을 때 (기회손실 : -0.18)
- 신용대출신청 승인 → 신용도가 높은 고객 맞았을 때(기회 : +0.08)혹은 틀렸을 때 (기회손실: -0.08)
- 1인당 기대 수익액(기대가치) 계산하기
[reference]
- IAML2.22: Classification accuracy and imbalanced classes
- accuracy 만 사용하면 모델 성능에 대해 잘못된 판단을 내릴 수 있다.
- imbalanced-learn
- 불균형이 극심한 경우 => 비지도(혹은 준지도) 학습 알고리즘으로 문제를 해결할 수 있다.
- 머신러닝 기반
- 딥러닝 기반 방법